Advancing Text-Driven Chest X-Ray Generation with Policy-Based Reinforcement Learning
May 14, 2024· ,,,,·
0 min read
,,,,·
0 min read
Woojung Han*
Chanyoung Kim*
Dayun Ju
Yumin Shim
Seong Jae Hwang
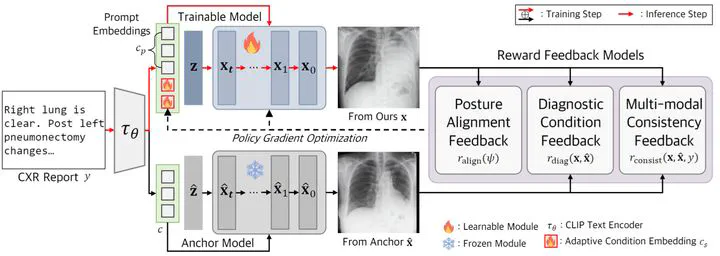 Image credit: Unsplash
Image credit: UnsplashAbstract
Recent advances in text-conditioned image generation diffusion models have begun paving the way for new opportunities in modern medical domain, in particular, generating Chest X-rays (CXRs) from diagnostic reports. Nonetheless, to further drive the diffusion models to generate CXRs that faithfully reflect the complexity and diversity of real data, it has become evident that a nontrivial learning approach is needed. In light of this, we propose CXRL, a framework motivated by the potential of reinforcement learning (RL). Specifically, we integrate a policy gradient RL approach with well-designed multiple distinctive CXR-domain specific reward models. This approach guides the diffusion denoising trajectory, achieving precise CXR posture and pathological details. Here, considering the complex medical image environment, we present “RL with Comparative Feedback” (RLCF) for the reward mechanism, a human-like comparative evaluation that is known to be more effective and reliable in complex scenarios compared to direct evaluation. Our CXRL framework includes jointly optimizing learnable adaptive condition embeddings (ACE) and the image generator, enabling the model to produce more accurate and higher perceptual CXR quality. Our extensive evaluation of the MIMIC-CXR-JPG dataset demonstrates the effectiveness of our RL-based tuning approach. Consequently, our CXRL generates pathologically realistic CXRs, establishing a new standard for generating CXRs with high fidelity to real-world clinical scenarios.
Type
Publication
Medical Image Computer Vision and Pattern Recognition (MICCAI'24 Early Accept & SPOTLIGHT)